REXX怎么保存"Find ALL"的结果
最近的项目经常跟MQ打交道,将输入数据填在一个dataset里面提交给MQ解析,字段之间用逗号隔开。所以在测试MQ接口的时候会经常一边对着FSD文档,一边数dataset里面的逗号个数的情况。数多了就烦了。其实到今天才想起来可以用一个"FIND ALL"的ISPF命令。
FIND ',' ALL
这样,逗号的个数就不用数了,直接显示在屏幕右上角。
既然这样,利用REXX应该可以保存这个“FIND ',' ALL'的结果。 研究了一下,可以这样:
编辑IBMUSER.REXX.EXEC(CHECK)这个member,输入如下的macro:
1 ADDRESS ISPEXEC
2 "ISREDIT SEEK ALL ','"
3 "ISREDIT (COUNT) = SEEK_COUNTS"
4 SAY "Comma number: "!! COUNT !! "'!'"
5 EXIT 0
打开MQ的DATASET,比如 ...
more ...Rexx顺序处理文件所有行
这是典型的自上而下扫描一个dataset中每一行,而做相应处理的Rexx脚本,几乎所有的处理文件I/O的Rexx脚本都会涉及到:
ADDRESS TSO
indataset = 'IBMUSER.REXX.EXEC(INFILE)' /*read in input file */
"alloc f(fin) ds('"indataset"') shr reuse"
"execio * diskr fin (finis stem in."
"free f(fin)"
do i=1 to in.0 /*loop in file until the last line reached */
one_line = strip(in.i)
call ...ISPF下如何去掉程序的第72至80列
个人不是很喜欢ISPF 3.13提供的两个Dataset比较的功能,总觉得看得不是很直观。平时还是比较习惯用windows下面的winmerge这个软件来比较。但是有个问题,就是比较的两个程序经常在第72列至80列的行号不一致,导致没法比较。所以这里就来总结一下如何去掉DATASET的中烦人的第72列至80列内容。
方法一:直接在ISPF下面用命令去掉
这是最直接最快的办法。去掉第72列至80列的命令有下面两个:
NUM ON; UNNUMB
C P'^' ’ ’ 73 80 ALL /* Changes all non-space characters to spaces in col 73 to 80*/
方法二:用第三方脚本实现
上面的方法如果是只有少数几个程序,那么手动命令去掉第72列至80列没什么。但是如果你一下子需要对几百个dataset或者同一个PDS下面的所有member去掉第72列至80列,则最好最快的办法是将所有代码通过FTP下载到本地,然后用第三方脚本语言(如VB,Phthon,Ruby,JS等)来解决。
这里是一段自己的Ruby脚本,作用是将C:\prod ...
REXX学习笔记
最近在学习Rexx脚本,打算做一些自动化。归纳了些点总结下放在这里以备查询。
一些基本概念
- REXX:
REstructured eXtended eXecutor (REXX) language扩充结构化执行语言 - REXX中变量无需事前定义
- Debug REXX:用REXX TRACE或者用interactive debug facility来定位error
- SAA Procedures Language:REXX的子集,在TSO/E,CICS,IMS等多种环境中应用
- 要运行REXX exec,必须至少有一种可用的
Host command environments。默认的是TSO。还有MVS,LINK,LINKMVS,LINKPGM,ATTACH,ATTCHMVS,ATTCHPGM,ISPEXEC,ISREDIT,CONSOLE,CPICOMM,LU62,APPCMVS等等,常用的有 ...
Watir自动为优酷视频刷顶
很喜欢优酷上面的一个节目,想帮帮它早日升到排行榜怎么办?写个脚本好了。
#encoding: UTF-8 #添加这一行才可以处理中文
require 'rubygems' #gem install xxx --no-ri --no-rdoc
require 'timeout'
require 'watir-webdriver'
b = Watir::Browser.new(:firefox, {:profile => 'default'})
b.driver.manage.timeouts.implicit_wait =60 #默认的等待页面加载30秒若还未加载完成则会跑出timeout异常,这里可以修改成60秒
b.goto 'http://v.youku.com/v_show/id_XNTE5MTY3NzI4.html' #假设我现在要为这个视频刷“顶”
for i in 1..100 #假设我这里要"顶 ...Ruby分割文件
自己小试的ruby程序,用于将一个dictionary.txt分割成多个小一点的子文件,不然每次都操作dictionary.txt显得很笨重。想把dictionary.txt按照字母首a~z,每个首字母再按长度分为长度为1~3的比如a_1to3.txt,长度为4的a_4.txt,长度为5的a_5.txt,长度为6的a_6.txt,长度为7的a_7.txt,长度为8的a_8.txt,以及长度大于8的others。这样,dictionary.txt最后被分割成了6x26+1=157个子文件,就不会像处理dictionary.txt那样笨重了,毕竟CPU有限。
为啥wordpress里面粘贴代码都只有黑乎乎的一片呢,可爱的语法高亮在哪里?还是喜欢五颜六色的代码段啊,上图吧:
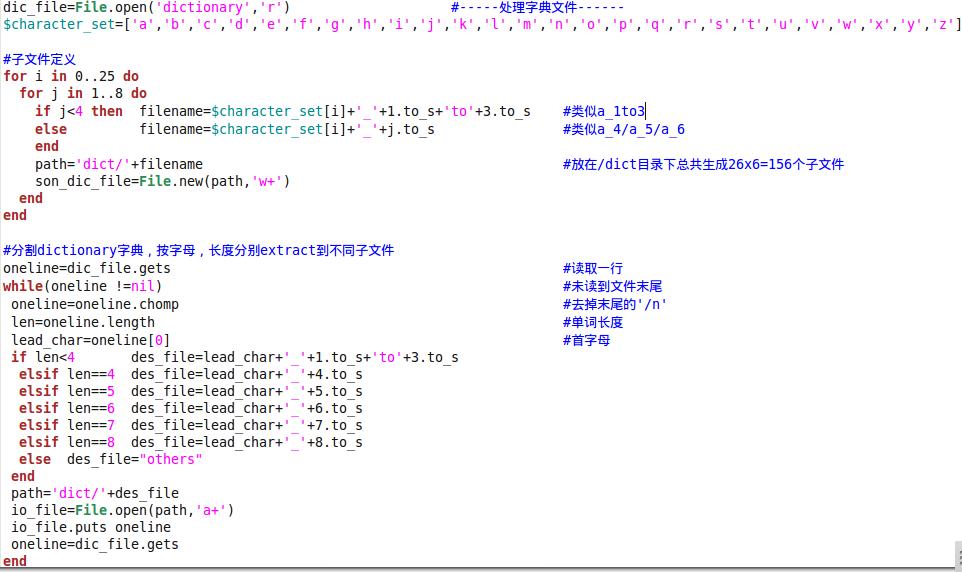
只需10秒左右,就生产了157个文件,a_1to3,a_4,a_5...b_1to3,b_4,b_5...z_1to3,z_4 ...
more ...Watir重新连接路由器
有些网站对IP有所限制,如果你不想用代理IP的话,那么有一个看起来有点傻但却很简单的办法可以起到更换IP的效果——将路由器断线重连。因为家用宽带路由器的IP基本上是由运营商动态分配的,所以你只要登陆路由器,点击断线,等内网发送数据包请求至外网的时候,路由器重新连接上,IP也随之改变了。这方法虽然笨,但也实用。下面是用Watir脚本实现的,仅供参考。
#encoding: UTF-8 #添加这一行才可以处理中文
require 'rubygems' #gem install xxx --no-ri --no-rdoc
require 'timeout'
require 'watir-webdriver'
b=Watir::Browser.start 'http://admin:admin@192.168.1.1' #用此方法可以避开用户密码登陆框 用户名密码这里都是admin
b.frame(:name,"bottomLeftFrame").link(:id,'a0').click #点击 ...Watir收集最快的代理服务器ip列表
这个脚本所做的事情是从www.cnproxy.com网站上取得最新的10页代理服务器的ip,将它们写到proxy_ip_list.txt文本文件中去。包括每一个代理服务器的响应时间。
#encoding: UTF-8 #添加这一行才可以处理中文
require 'rubygems' #gem install xxx --no-ri --no-rdoc
require 'timeout'
require 'watir-webdriver'
time1=Time.now
proxy_ip_lists=File.new("proxy_ip_lists.txt",'w')
def char2int(str)
for i in 0.. str.length-1
if str[i]=='z' then str[i]='3'
elsif str[i ...Watir设置代理
#encoding: UTF-8 #添加这一行才可以处理中文
require 'rubygems' #gem install xxx --no-ri --no-rdoc
require 'timeout'
require 'watir-webdriver'
profile = Selenium::WebDriver::Firefox::Profile.new
profile.proxy = Selenium::WebDriver::Proxy.new :http => 'my.proxy.com:8080', :ssl => 'my.proxy.com:8080'
browser = Watir::Browser.new :firefox, :profile => profile
Watir登陆谷歌搜索关键字
#encoding: UTF-8 #添加这一行才可以处理中文
require 'rubygems' #gem install xxx --no-ri --no-rdoc
require 'timeout'
require 'watir-webdriver'
begin
Timeout::timeout(10) do |timeout_length| #在国内,google经常被墙导致连接超时
b.goto 'http://www.google.com.hk/webhp?hl=zh-CN&sourceid=cnhp'
end
rescue Timeout::Error => e
puts "page is not completed loaded, program will go on procesing ...